
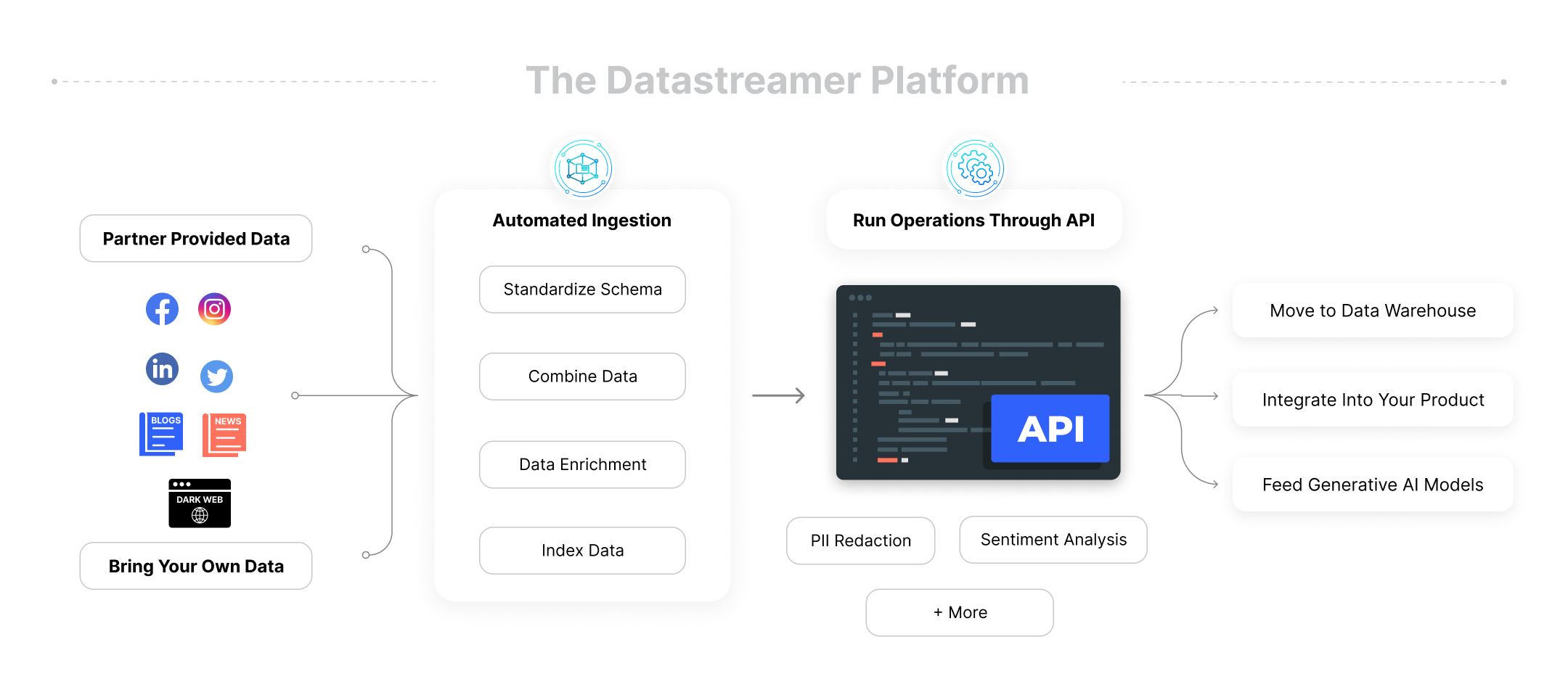
Focus on your product, not your plumbing
Working with unstructured data is typically a bottleneck for organizations. In-house data teams spend enormous effort to source, enrich, store, and deliver this data. In most cases, this leads to slow speed-to-market and a high investment of resources. The Datastreamer platform solves this dilemma.
High Speed Data Integration
Datastreamer’s extreme-performance modular pipeline, supports real-time monitoring and mission-critical business features. Datastreamer brings together high-performance pipeline technology with AI-driven ETL and schema unification technology.
Bringing new data sources of any size into your pipeline is now the easiest thing on your roadmap.
Enriched & Enhanced
Datastreamer’s component-driven pipeline enables you to apply AI/ML to your data instantly. Leverage the capabilities and releases of your data science team within the Pipeline.
In addition, instantly utilize the dozens of enrichments, models, and other AI capabilities from our Partner network.