
Data365
This documentation covers best practices and how to setup and use Data365 sources.
Best Practices
Best Practices
The below are best practices suggested and advised by the Datastreamer and Data365 team. In the case of any support needs, the team will suggest the following of the best practices for the smoothest experience.
- Many sources have limits and restrictions in place. It is better to run many small tasks across small timeframes, as opposed to larger tasks across longer timeframes.
- The coverage of Data365 sources are not sampled, and therefore if you are seeing lower volumes than expected, the tasks should be reviewed and seen how they can be simplified.
- In order to collect all posts over a long period of time, we recommend dividing into many small periods. For example, you can specify the time period from 2023-04-01 to 2023-04-02 and max_posts=300 and thus collect all posts during that time. And so on for every day or a longer interval, depending on the frequency of expected content.
- Be aware of Collection Task Limits! See "3.1 Collection Limits" below
Data365 Collection Tasks
Have you registered your token?
If you have registered your Data365 Token in the Datastreamer platform, proceed to step 3. If not, being at step 1.
1. Getting Started
To get started with Data365, you will first need to have an access token from Data365 (please contact us if you don’t already have one).
NOTE: for the cURL examples below, we've injected twitter_keywords as a possible DataSourceName. Feel free to use any of the possible Data365 sources available that are found within the Response Body of View your new connected sources
2. Register your Data365 Token with Datastreamer.
Full documentation:
Full documentation is available here: https://docs.datastreamer.io/docs/connecting-compatible-sources. A snippet is listed below.
2.1. Register your Token.
curl --location --request PUT 'https://api.platform.datastreamer.io/api/data-sources/data365' \
--header 'Content-Type: application/json' \
--header 'apikey: {YourDatastreamerApiKey}' \
--data '{
"token": "{YourData365AccessToken}"
}'
2.2. View your new connected sources
curl --location 'https://api.platform.datastreamer.io/api/data-providers/data365' \
--header 'apikey: {YourDatastreamerApiKey}'
Using the above command you can see all the current supported sub-data sources from Data365.
3. Create your tasks
Creating your tasks for Data365 collection involves specifying the source in your URL, and needed data within the body.
You can use the following command to create your first batch of tasks.
curl --location 'https://api.platform.datastreamer.io/api/data-providers/data365/twitter_keywords' \
--header 'Content-Type: application/json' \
--header 'apikey: {YourDatastreamerApiKey}' \
--data '{
"tasks": [
{
"value": "hellokitty",
"from_date": "2023-08-01",
"to_date": "2023-08-17",
"update_interval": 300,
"auto_update_expire_at": "2024-01-01T15:00:00",
"parameters": {
}
}
]
}'
Some explanations:
- Depending on the data source, value could be the profile, keywords, location_id, music name or hashtag (without #).
- You will need to specify a from_date and to_date in yyyy-mm-dd format.
- If you want it to be a repeated task, you’ll need to specify the update_interval and auto_update_expires_at
- If the auto_update_expires_at is in the past, the task will be executed only once.
- If the upstream data365 has more parameters you want to use, put them under parameters and it will be added to the request.
- You can add multiple items to the same source.
- You can add multiple times the same or different items, it will always add to the current list.
- For instagram_location, you can try to find out the location id via this guide
Here are some of the sample value for each data source
| Name | Reference |
|---|---|
| facebook_hashtag | tesla |
| facebook_keywords_latest | toyota |
| facebook_keywords_top | samsung |
| facebook_profile | cristiano |
| instagram_hashtag | bitcoins |
| instagram_location | 212988663 |
| instagram_profile | spacex |
| linkedin_company | microsoft |
| linkedin_keywords | italy |
| linkedin_member | satyanadella |
| tiktok_hashtag | hellokitty |
| tiktok_keywords | world cup |
| tiktok_music | Breakfast-Challenge-Song-Slowly/6669854674113317638 |
| tiktok_profile | sssorn_chonnasorn |
| twitter_keywords | covid-19 |
| twitter_profile | cp24 |
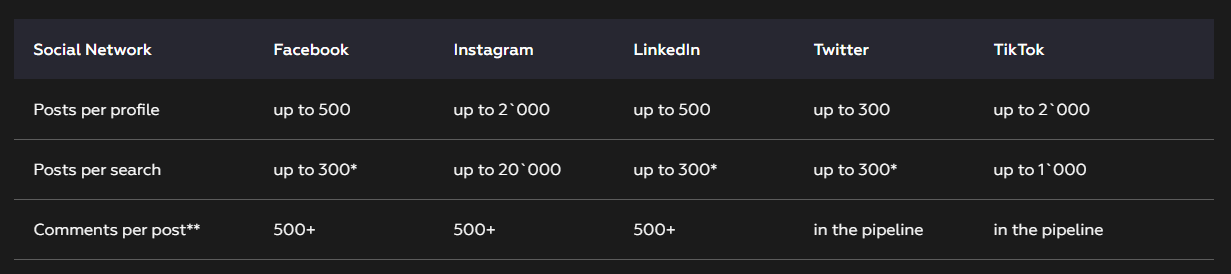
3.1 Task Limits
The following task limits are present.
- In order to collect all posts over a long period of time, create multiple tasks across many small periods. For example, you can specify the time period from 2023-04-01 to 2023-04-02 and max_posts=300 and thus collect all posts during that time. And so on for every day or a longer interval, depending on the frequency of expected content.
4. Listing Your Tasks
You can list all the tasks under a certain source (putting the data source name in the URL)
curl --location 'https://api.platform.datastreamer.io/api/data-providers/data365/twitter_keywords' \
--header 'apikey: {YourDatastreamerApiKey}'
You can also filter tasks by date or status and define the number of records to be returned.
curl --location 'https://api.platform.datastreamer.io/api/data-providers/data365/twitter_keywords?start=1&count=200&from=2023-10-01T00:00:00Z&to=2023-12-05T23:59:59Z&status=started' \
--header 'apikey: {YourDatastreamerApiKey}'
Some notes:
- The list of all tasks also has task status for each item, but it might be different than the status you get from individual status - this is caused by upstream (data365) task management. Generally speaking, the status in the list reflects the last time a task was executed and the status in the individual reflects the newest/next time the task is executed.
5. Start/Stop and Check tasks
Once you have the list of tasks, you need to start them in order to get the data. You can either start all of them (put the correct data source name in the URL)
a. Start All
curl --location --request PUT 'https://api.platform.datastreamer.io/api/data-providers/data365/twitter_keywords/start-all' \
--header 'Content-Type: application/json' \
--header 'apikey: {YourDatastreamerApiKey}'
b. Start a Single task
Start an individual task (using the TaskId from listing or creation)
curl --location --request PUT 'https://api.platform.datastreamer.io/api/data-providers/data365/twitter_keywords/{TaskId}/start' \
--header 'apikey: {YourDatastreamerApiKey}'
c. Cancel All Tasks
Similarly, you can cancel the tasks you started either in batch
curl --location --request POST 'https://api.platform.datastreamer.io/api/data-providers/data365/twitter_keywords/cancel-all' \
--header 'apikey: {YourDatastreamerApiKey}'
d. Cancel a Single Task
or individually
curl --location --request POST 'https://api.platform.datastreamer.io/api/data-providers/data365/twitter_keywords/{TaskId}/cancel' \
--header 'apikey: {YourDatastreamerApiKey}'
e. Check Task Status
Usually, the task takes 10-30 minutes to get executed, and you can check the status of the tasks via
curl --location 'https://api.platform.datastreamer.io/api/data-providers/data365/twitter_keywords/{TaskId}' \
--header 'apikey: {YourDatastreamerApiKey}'
Once the status becomes “complete” or “finished” your data is ready to be consumed.
f. Remove a task
Where if you want to remove a task, use the following, putting the correct data source name and task id in URL):
curl --location --request DELETE 'https://api.platform.datastreamer.io/api/data-providers/data365/twitter_keywords/{TaskId}' \
--header 'apikey: {YourDatastreamerApiKey}'
6. Consume the data you have received
Once your tasks are completed, the data are ready to be consumed via normal Datastreamer search/count APIs. For example, the following query will be searching in the data you have in data365_instagram_location. (You’ll need to add data365_ before the name of the data source).
Note that it is important to include a date range in your query for
doc_dateorcontent.publishedfields, the default date range if not included is past 30 days by default, so it's recommended to include a date range in your query. See example below for retrieving documents using a date range filter oncontent.publishedfield.
Even though there is no organization on the data source name, the search API implementation ensures it hits the proper index.
curl --location 'https://api.platform.datastreamer.io/api/search?keep_alive_seconds=60' \
--header 'Content-Type: application/json' \
--header 'apikey: {YourDatastreamerApiKey}' \
--data '{
"query": {
"from":0,
"size": 100,
"query": "hellokitty AND content.published: [2022-10-01 TO 2023-10-01]",
"data_sources": ["data365_twitter_keywords"]
}
}'
You are all set!
If you want to explore with a sample source before diving into production usage, try out these sample sources: https://docs.datastreamer.io/docs/sample-sources.
Task Restrictions
The following limits are in place for task creation:
- 498 characters for twitter search query
- When you create a task with data365_twitter_profile, make sure you don't use operators. It's best to create one-task-per-profile.
- When you create a task with data365_twitter_keywords, you can use operators (AND, OR)
for Twitter, up to 300 posts per search
Updated 5 months ago